材料開発の現場において、AIを活用し、開発期間の短縮やコスト削減を実現するマテリアルズ・インフォマティクス(MI)への期待は高まっています 。
しかし、多くの企業で「データはあるけど、活用できない」という課題に直面し、MIの推進が停滞しています。MIの成功のカギは、AI活用に不可欠な「実験データの構造化」にあります。
このセミナーでは、研究開発現場が抱える具体的な課題を明らかにし、その解決策となる「データ構造化」の具体的な手法とケーススタディをご紹介します。
MIは、材料開発の期間短縮・効率化を実現する技術です。
AIやシミュレーションを駆使するためには、過去の実験データをうまく活用できる形に整えることが大切です。そのため「データの構造化」は、MIを進めるための基盤だと考えています。
あらためて、MIの3つの目的は次のとおりです。
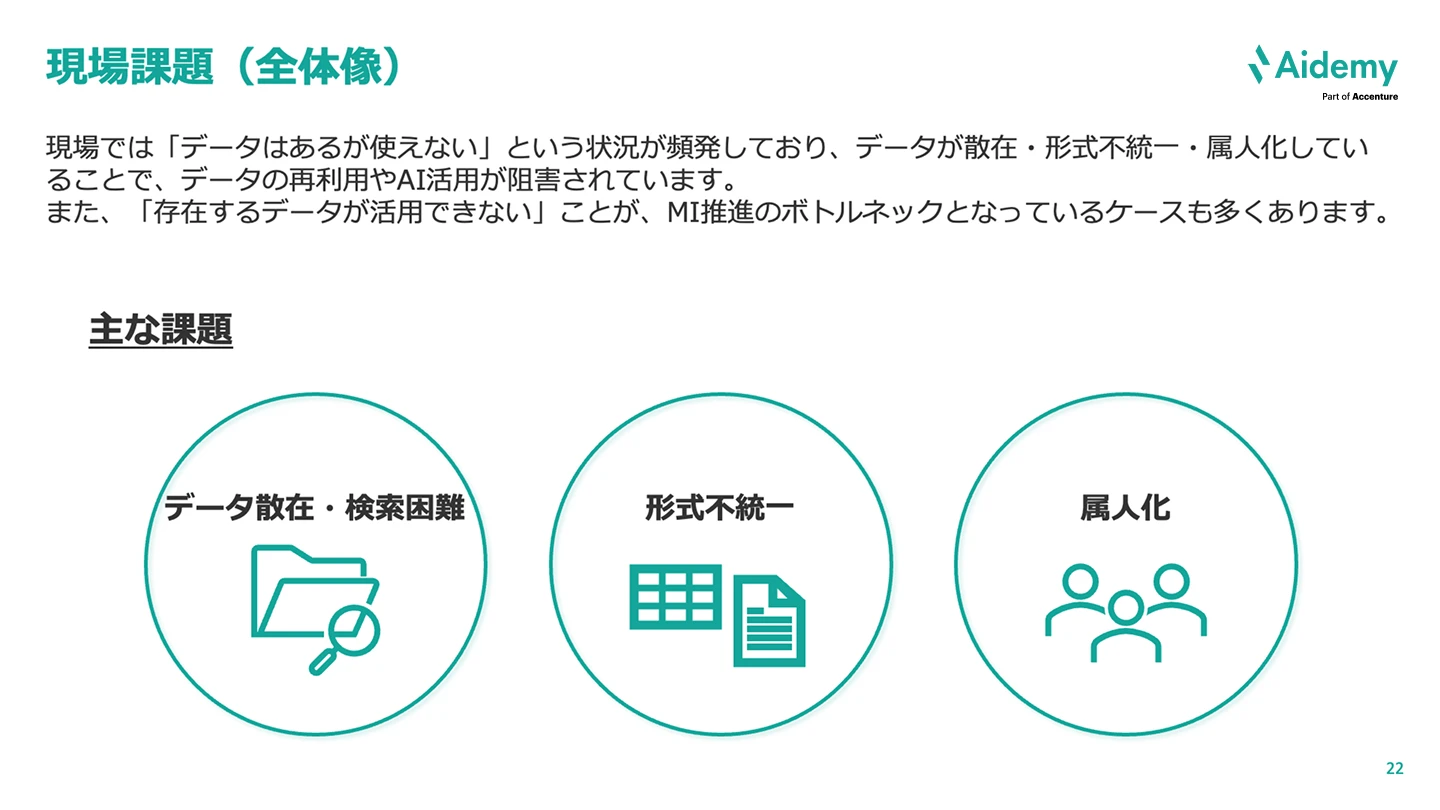
現場課題の全体像という点で、私もMI導入についてお客様と打ち合わせをする機会がありますが、データはあるけど使えない状態や状況であったり、各研究員が使っているデータフォーマットが異なるため、AIや機械学習などが利用できないという声をよく聞きます。これらの課題は、多くの現場で共通するのではないかと思います。
つまり、「データが存在するのに活用できない」ということが、MIを推進することのボトルネックになっているケースが多いようです。
お客様のさまざまな声を3つに分類すると、1つ目はデータが散在していたり、検索が難しかったりすること、2つ目は形式・フォーマットが人によって異なっているということ、3つ目が属人化となります。
これら3つの課題について、詳しく説明しましょう。
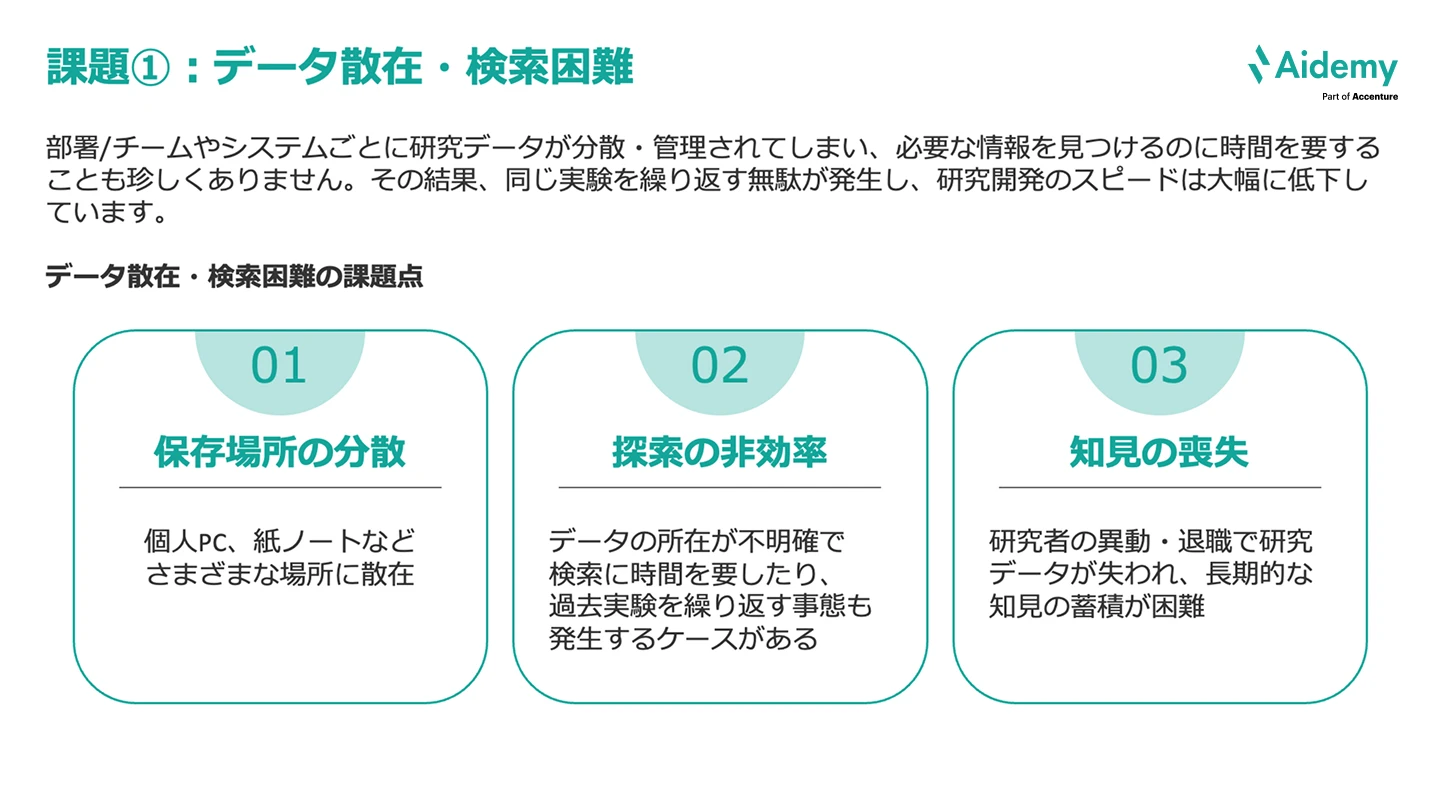
現場では、部署やチーム、システムごとに研究データが分散・管理されてしまい、必要な情報を見つけるのに時間を要することが珍しくありません。
原因として、次の3つが考えられます。
これらによって、データ検索に時間がかかったり、AIが活用できなかったりと、研究開発の非効率化が起きてしまっている、という状況がよくあります。
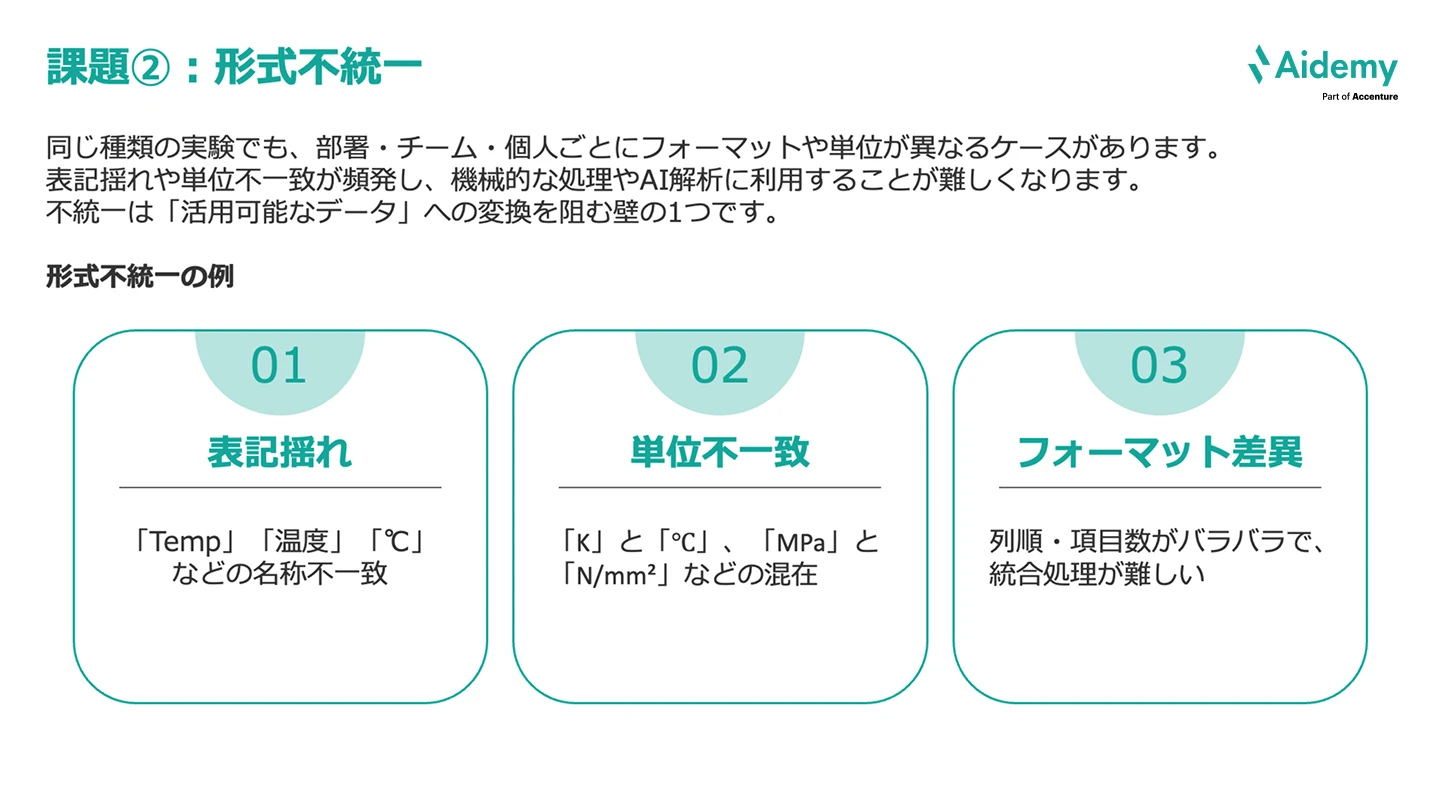
同じ種類の実験でも、部署・チーム・個人ごとにフォーマットや単位が異なるケースがあります。
次の3つが代表的な例です。
表記揺れや単位不一致が頻発し、機械的な処理やAI解析に利用することが難しくなります。これらの不統一は「活用可能なデータ」への変換を阻む壁のひとつです。
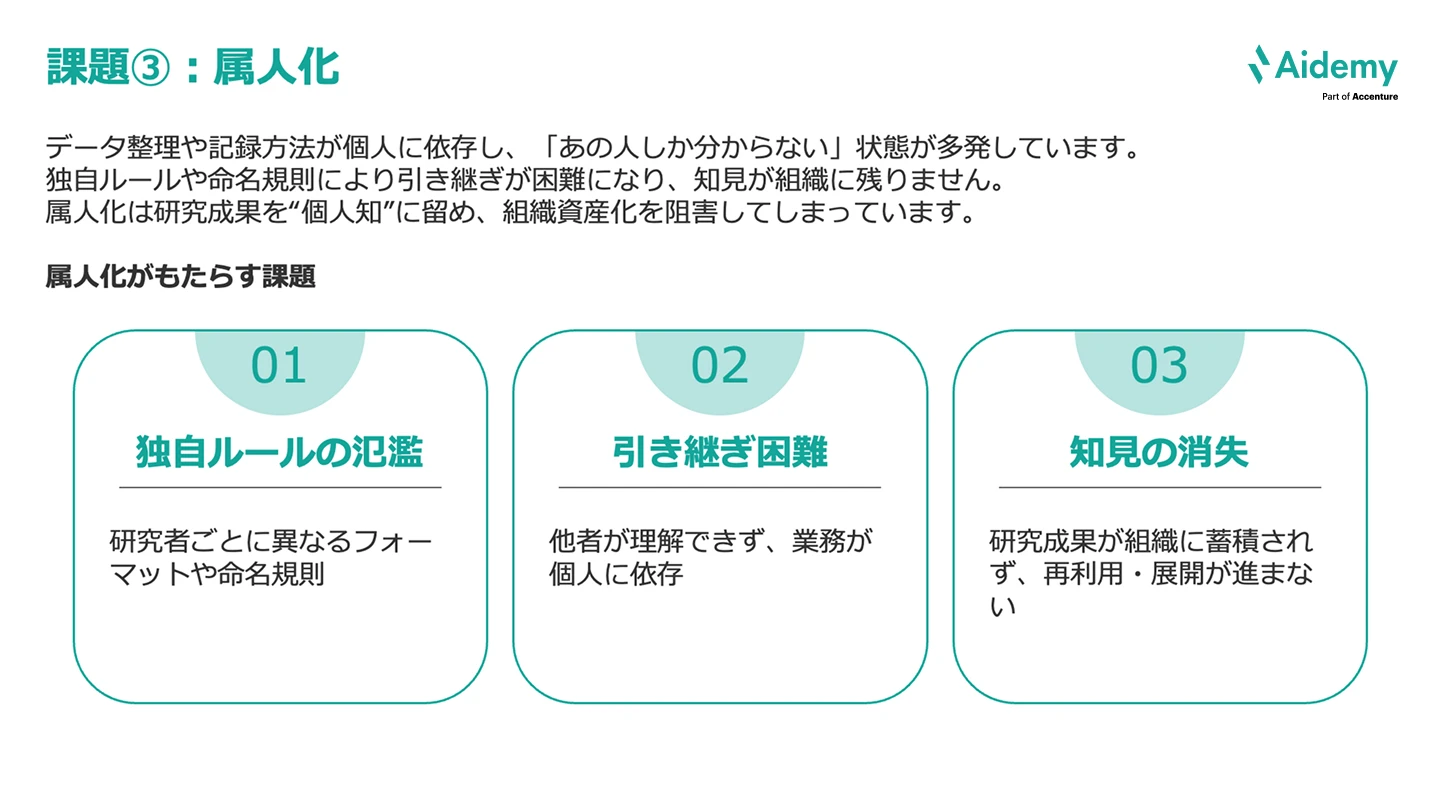
データ整理や記録方法が個人に依存し、「あの人しか分からない」「あの人なら分かるよ」という状態が頻発していることが、私自身もよく耳にします。
課題としては、次の3つがあります。
独自ルールや命名規則により引き継ぎが困難になり、知見が組織に残りません。属人化は研究成果を“個人知”に留め、組織資産化を阻害してしまっています。
それでは、本題に入っていきましょう。 一般的な「データ構造化」も含めて話していきます。
データ構造化の要素とメリット
データ構造化の3つの要素は次のとおりです。
これらの要素を満たすデータ構造化を推進することで、次のようなメリットが生まれます。
これらの構造化を実現し、研究開発部門における材料開発を加速させるためのデータ蓄積プラットフォームとして、アイデミーには「Lab Bank」があります。Lab Bankを活用することで、データの一括管理、高い汎用性、そしてMIモデルによる物性予測機能を提供し、材料開発の時間とコストを削減できます。

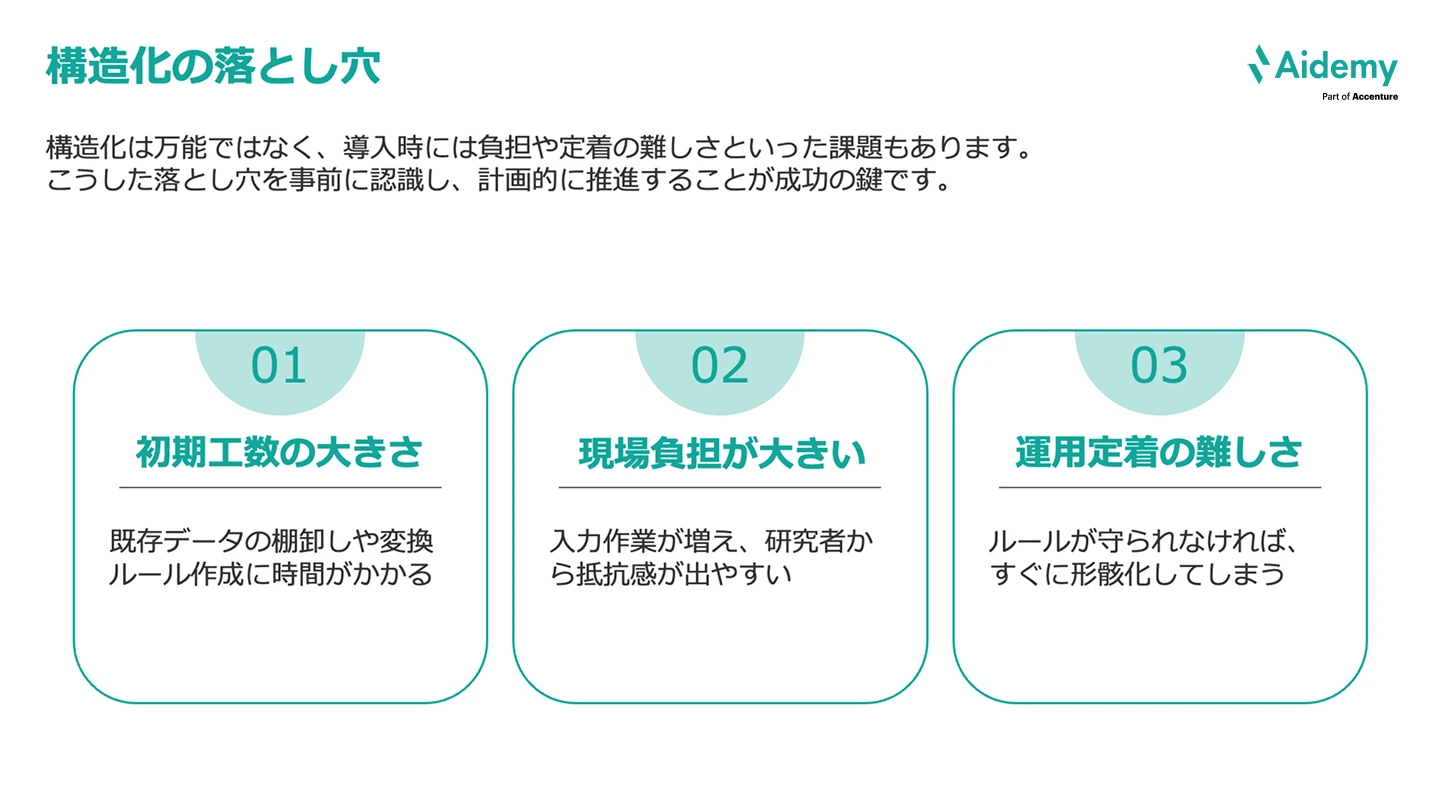
さて、データ構造化は万能ではなく、導入時には負担や定着の難しさといった課題があることも押さえておきましょう。
具体的には、次の3点が課題として挙げられます。
補足すると、これらの課題によって、昔のやり方のほうが慣れているからと、勝手に運用方法を戻してしまう可能性があります。
これらの落とし穴を事前に認識し、計画的に推進することが成功のカギです。
このセミナーでの「実験データの造化」について、簡単に定義をしておきましょう。
私たちは、実験データの造化とは「AIや機械処理で検索・分析できるように整理すること」と定義しています。単なるファイル管理ではなく、データを使える形に整えることを意味します。このことが、MI推進の前提条件であり、研究開発の効率化の出発点となります。
実験データの造化に必要な要素は、次の3つです。

今回ご紹介する事例の背景とゴールについて説明します。
まず、背景としては、
となります。
ゴールは、
としています。
実験データは研究者ごとに形式が異なるため、そのままでは分析や共有が困難です。本ケーススタディでは3つのExcelファイルを共通フォーマットに構造化し、最終的に1つのCSVに統合します。
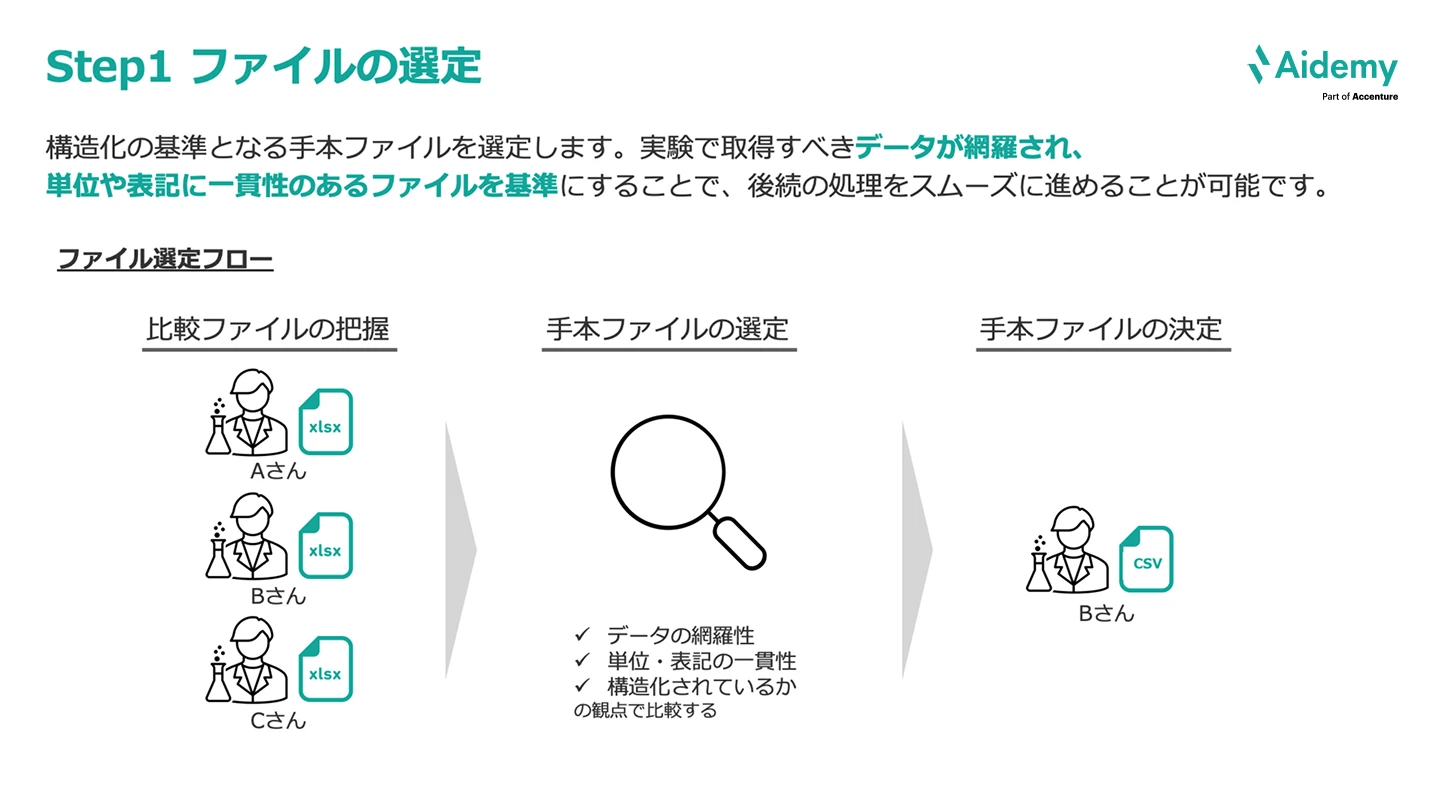
構造化の基準となる手本ファイルを選定します。実験で取得すべきデータが網羅され、単位や表記に一貫性のあるファイルを基準にすることで、後続の処理をスムーズに進めることが可能です。
ファイル選定のフローとしては、次のようになります。
Aさんのファイルは、1実験1行になっておらず、構造化しづらい形式であり、網羅性△、一貫性◯、構造化×。
Bさんのファイルは、1実験1行になっており、他のファイルよりも網羅性を担保できているため、網羅性◯、一貫性◯、構造化◯。
Cさんのファイルは、日付行があり、構造化されていないといったことから、網羅性△、一貫性△、構造化×。
このように評価した上で、Bさんのファイルを手本ファイルとすることに決定しました。
※どのファイルを手本ファイルとした場合でもデータ構造化を行うことは可能です。しかし、効率的なデータ構造化を行うために、手本ファイルの選定を行います。

次のステップでは、Step 1で選んだ手本ファイルをともに、生成AIを用いてデータをCSV形式に構造化します。これにより、異なるフォーマットの実験記録を統一的に整理できるようになります。
データ構造化の流れは、次のとおりです。

実際に、生成AIにプロンプトを入力する画面を見てみましょう。Aさん、Bさん、Cさんのファイルそれぞれを処理していきます。
一回ではうまくいかず、エラーが発生する場合もありますが、どのように処理を進めて欲しいのかを伝えることで、ブラッシュアップしながらフォーマットを作っていくことになります。
最後に、手本ファイルで作成した変換スクリプトを基準に、他のExcelファイルも同様にCSV化します。
CSVファイルを出力するPythonスクリプトを生成させることで、本ケーススタディのゴールを達成することができました。

生成AIを活用したデータの構造化をご紹介しましたが、やはりセキュリティ上の懸念を抱く方も多いと思います。
今回のケーススタディでは、ダミーデータを使用したため、そのままChatGPTに投入が可能でした。しかし、実際の実験データを既存のAIアプリなどにそのまま入れるのは基本的許されないケースもあるでしょう。
たとえば、OpenAIのChatGPTアプリの場合、デフォルトでは投入したデータは今後のGPTモデルの学習に使用されてしまう点であったり、学習への使用が無くとも、海外のAIサーバーにデータが送信される時点で一定のリスクが存在し、企業で許されるケースは少ないと考えています。
では、どのような回避策があるのかというと、次の2つがあると思います。
今回のケーススタディではデモデータを利用していたため、ChatGPTを活用したデータ構造化を行いました。
普段の業務で、ChatGPTやCopilotに研究データを入れることができるケースは稀であると考えています。ローカルLLMやデータのマスクなどの回避策を利用して生成AIを活用する道筋もあるかと思います
実際に本セミナー後、生成AIを活用した構造化を実践してみて、お困りごとがあればぜひアイデミーにお声がけください。


サービスに関する詳細や
導入事例についてご紹介した
資料をダウンロードいただけます。

お悩みや課題に合わせて
活用方法をご提案いたします。
お気軽にお問い合わせください。